
.jpg?width=832&name=Untitled%20design%20(6).jpg)
Data science is at the core of Entelo, improving search relevance (Entelo Search), fine-tuning candidate recommendations (Envoy), and powering outreach and candidate insights (Entelo Track and Entelo Insights). More specifically, machine learning drives these automated and data-driven features – constantly running in the background to make Entelo smarter and more efficient. However, if improperly used, machine learning has the potential to introduce biases in the system. In this article, I describe how Entelo eliminates those potential biases.
Machine Learning
Machine learning is a subset of data science that uses algorithms to predict outcomes without being explicitly programmed to do so. A machine learning model is trained on a large amount of data to identify prevalent patterns and apply them to make predictions on new unseen data. The machine learning pipeline usually includes the following steps:

Bias
A model, however, is only as good as the data it is trained on – as the experts put it, “garbage in garbage out”. The data used to train the model may contain biases, which if not handled properly, allow the model to learn such biases. If that model is then used to make important predictions, it could lead to unfair decisions.
Take, for example, word embeddings, a set of techniques that represent words or phrases in a large text dataset as vectors of numbers. Word embeddings are widely used in machine learning and natural language processing models to find relationships between words and phrases – words that are similar or related will likely have closer embeddings in the vector space.
If the dataset from which word embeddings are extracted have certain biases, the embeddings can learn such biases. Analyzing embeddings generated from Google News articles, researchers found that the word “programmer” is mapped much more closely to the word “man” than to the word “woman.” Along those same lines, it’s no surprise which word was more closely linked to “homemaker.”
Similar results were also seen in names where male names like “John” was closer to the word “programmer” than to female names like “Mary”. If the embeddings are used in search ranking or machine learning models to recommend candidates, it is possible that when two candidates with similar profiles named Mary and John show up in search for a programmer, the model could rank John higher than Mary for the role.
Preventing Bias
Although it may not be possible to completely eliminate biases from data, we actively take measures in every stage of the machine learning process to prevent biases from surfacing in our products. We also work on more proactive initiatives to improve the representation of diverse candidates in our search results and candidate recommendations.
Model Features
Rather than blindly applying algorithms to our data, Entelo removes any feature that could introduce discrimination into our insights. This includes:
- Name, gender, and ethnicity – Given the word embedding biases related to name/gender and occupations, we do not rely on a candidate’s name, gender, or ethnicity when generating the embeddings that fuel our machine learning models.
- Location histories – Location is used to filter candidates only when a user explicitly states a preference for a specific location. Eg. “Software Engineer within 50 miles of San Francisco, CA”. Other than this use case, current location or location histories are not used in any of our data science models. This is due to the potential for correlation between a person’s race or ethnicity and their location which the model could then learn.
- Career gaps – Our analysis shows that women on average have 20% longer career gaps than men with similar experience. If our model were to identify a correlation between career gaps and likelihood of candidacy, a bias towards women would become ingrained in predictions.
- School names – Educational background plays an important role in informing recruiting decisions, however, school names sometimes contain information that could identify a person’s gender or ethnicity (e.g. “Cummins College of Engineering for Women”). Similar to the correlation between gender and names, this educational information presents the same issues with biases and therefore is not included in Entelo’s algorithms.
Explaining prediction
Critics of machine learning models see them as a “black box” because it is not readily obvious how or why a particular prediction was made. To increase the transparency of our algorithms, we don’t just show the prediction but also explain why a certain prediction was made. By making machine learning more transparent we are allowing our users to directly evaluate the model.
For example, More Likely To Move shows a sliding scale of a candidate’s likelihood to change jobs in the next 90 days. Beneath this scale users can find a list of factors that determined this rating:
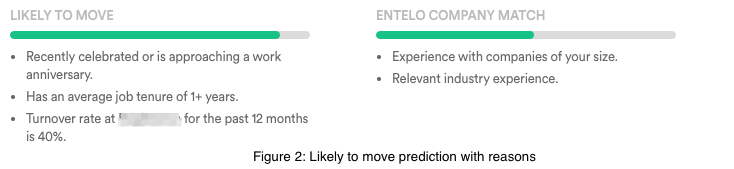
Improving representation of diverse candidates
We don't just stop at preventing biases from surfacing in our models, we also actively work on functionalities that improve the representation of diverse candidates.
Peer-based skills:
Female candidates on average list 16% fewer skills on their resume compared to their male counterparts, implicating keyword searches as inherently biased towards male profiles. To correct for this, Entelo’s algorithms infer skills for candidates based on information reported by their peers, leading to an increase of between 10 and 50 percent in the proportion of female candidates in the top 100 searched skills on Entelo:

Inclusive language:
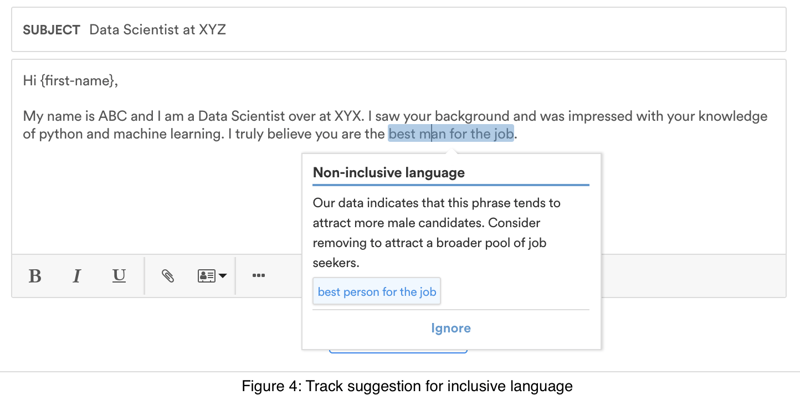
We analyzed over a million recruiting emails and discovered that 28% of emails contained biased language. We also found that the usage of gender-biased language negatively impacted email response rates. The response rate of female candidates shows up to 10% drop when the email contains biased language. As a part of our Track messaging insights, we identify words and phrases that are gender-biased and suggest alternate neutral terms to make the outreach more inclusive.
Curious how Entelo can help you eliminate biases within your own recruiting processes? Request a walkthrough of our platform from one of our product experts and see for yourself!